It happened! You are entering the Data Science field. In your dreams you create cool neural networks, write a voice assistant, beat financial marketing. But… One of the most important and time-consuming moments is processing data.
For myself I created a cheat sheet to obtain data before the project. Data example
import pandas as pd #import pandas
import numpy as np #import numpy
df = pd.read_csv("AB_NYC_2019.csv") #read dataset and put it into df
Look at the first 3 lines to understand what the values look like:
df.head(3)

Demonstrating Column Information:
- Display all columns with types
df.info()
- and some more information about numeric columns:
df.describe()
Here we check few questions about dataset and create plan for next step:
- Does the number of lines in each column correspond to the total number of lines?
- What is data type in each column?
- Can we see target columns?
Let’s check values:
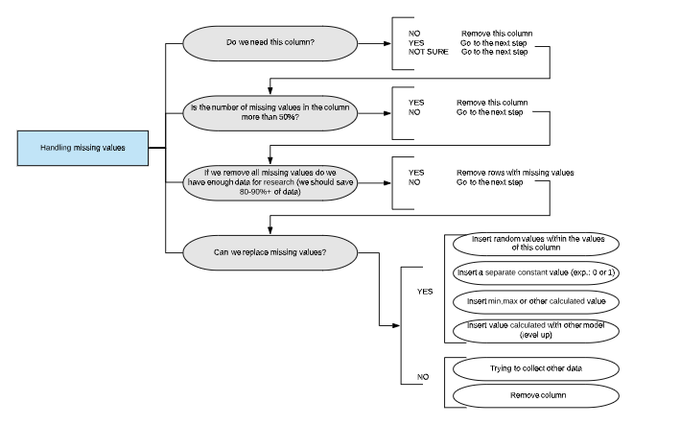
- missing values in columns:
import seaborn as sns sns.heatmap(df.isnull(),yticklabels=False,cbar=False,cmap='viridis')
- do we have columns with only one value in all rows (they will not affect the result):
df = df[[c for c
in list(df)
if len(df[c].unique()) > 1]]
- do we have duplicate values:
df.drop_duplicates(inplace=True) - work with empty values: